Java a la réputation d’être lourd et de ralentir la productivité des développeurs par rapport à d’autres technologies. Il paraît même qu’il serait en pleine agonie.
Il arrive d’entendre ici ou là «oui, java, c’est lourd, java c’est pas productif, java c’est tout pourri». Non, non Java n’est pas mort, c’est même un langage en pleine mutation.
Il faut bien avouer que Java a un passif ne jouant pas forcément en sa faveur. Les EJB 2 ne sont pas un exemple de simplicité et de concision. Pour créer un objet persistant en base de données, il faut éditer trois fichiers java, puis deux ou trois fichiers XML, et enfin prier de n’avoir rien oublié.
La suite était meilleure mais toujours pas optimale. Les fichiers de configuration de Struts 1, Spring 1 et Hibernate 2 étaient lourd à éditer et à maintenir, leur contenu étant très répétitif et mécanique. Concrètement, les noms des Actions Struts collent aux urls, ce qui implique qu’il y a rarement plus d’une implémentation pour les interfaces de ces API et que les noms des champs de base de données collent aux noms des propriétés des objets.
Depuis, Ruby On Rails a fait des émules, et on ne parle désormais plus que d’efficacité de développement, de « convention over configuration » (à savoir, par défaut on applique des conventions de nommage que l’on peut, au besoin, modifier dans des fichiers de configuration).
Les communautés Java se sont remises en question. Le constat a été simple et plutôt unanime :
– Java n’est pas une plateforme dédiée au web : le langage et ses API ne sont pas orientés dans ce sens. C’est un inconvénient pour la rapidité de développement, mais c’est par contre un avantage pour l’intégration dans les systèmes d’information.
– Les frameworks sont complexes pour pouvoir gérer des modélisations objets poussées et utilisent systématiquement des couches d’abstraction permettant une modularité maximale. On édite les mappings de Struts 1 pour faire correspondre des urls à des actions Java, on modifie les mappings de Spring pour emboîter les objets et enfin, on édite les mappings d’Hibernate. C’est un coût important lors de l’initialisation du projet pour garantir la capacité de l’application à évoluer. Mais pourquoi faut-il donc mettre en place toutes ces couches, contenant toujours les mêmes données rentrées mécaniquement, ce qui amène inexorablement les développeurs à faire des erreurs ?
Fort de ce constat, différentes solutions voient le jour. Certaines sont étranges, comme par exemple Essential Java 2, dont l’auteur propose de faire table rase de ces frameworks complexes pour utiliser des patrons de conceptions simples et bien connus. Les constats sont intéressants, mais par contre la solution proposée renie tout l’intérêt des frameworks, et le mode de développement auquel elle mène n’est certainement pas constructif :
– Je commence à travailler sur mon interface graphique directement avec les API servlet JSP – tout va bien, je suis bas niveau, je peux donc tout faire.
– Puis je commence à faire des formulaires, il faut que je fasse correspondre mes paramètres http avec des propriétés d’objets. Je trouve que c’est lourd à implémenter, alors :
- * soit je continue dans cette philosophie, et je finis par maudire celui qui a eu cette idée, parce que j’ai plein d’erreurs quand je commence à faire évoluer mon code et qu’il faut modifier ce mapping.
- * soit j’emploie une petite librairie (par exemple beanutils) pour associer les paramètres http aux objets Java. Ce qui revient, concrètement, à ré-implémenter Struts.
Les frameworks ne sont donc pas à renier, ce serait dommage de revenir en arrière sur tous les efforts de capitalisation qui ont pu être faits.
Les frameworks apportent leurs solutions
Les communautés des différents frameworks Java historiques ont bien compris le message, et proposent leurs solutions. Les nouveaux frameworks (ou leurs nouvelles versions) augmentent clairement l’efficacité de développement.
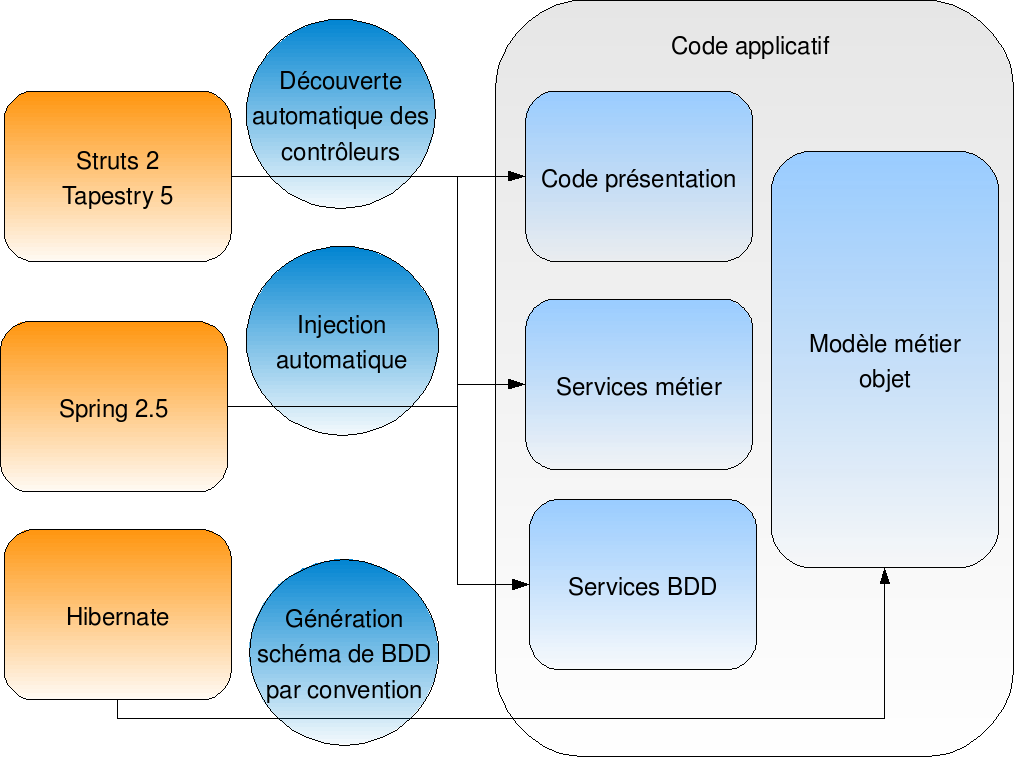
Struts 2 :
«Pourquoi devrais-je faire des objets dédiés à mon formulaire alors qu’ils correspondent à mon modèle métier dans 95% du temps ? Pourquoi devrais-je éditer un fichier de mapping, alors que les noms correspondent ?»
– On n’a plus besoin d’avoir une couche d’objets FormAction pour gérer les formulaires, on utilise directement les objets de son modèle
– La configuration n’est plus obligatoire, on peut se baser sur les conventions
– Pour plus d’informations, lire «Struts 1 / struts 2, lequel choisir ?»
Tapestry 5 :
«Pourquoi dois-je attendre un redémarrage de serveur pour modifier mes IHM ? Pourquoi éditer un fichier de configuration XML alors que mon code Java de présentation et le code HTML sont liés ?»
– L’accent est mis clairement sur l’optimisation des temps de développement dans cette version. On décrit les comportements que l’on veut avoir entre le template et le code Java par des annotations ou des conventions de nommage, il n’y a plus de fichiers de configuration.
– Ce que je fais tous les jours, je doit le faire simplement :
- * créer des composants réutilisables très rapidement
- * créer les formulaires d’édition de mes objets via un simple composant.
- * employer HTTPS simplement par une annotation
- * .etc.
– Les classes sont rechargées à chaud en cas de modification. Il n’y a donc pas besoin de relancer le serveur d’applications à chaque modification.
– On peut faire des tests unitaires sur les pages java, et tester ainsi son code sans les interfaces graphiques
– Pour plus d’informations, lire «Tapestry 5 : encore un peu de patience»
Spring 2.5 :
«Pourquoi devrais-je éditer un fichier XML à chaque fois que je dois définir ou utiliser un objet ? J’ai simplement besoin de préciser que la fonction est transactionnelle, et conservant la possibilité de brancher des proxys dans le futur.»
– Les packages à scanner sont définis dans un fichier de configuration XML initial, et ensuite les aspects gérés par Spring sont définis via des annotations. On peut ainsi décrire le fait qu’une dépendance doit être injectée par Spring, qu’une méthode est transactionnelle, ou qu’elle est accessible au travers d’un service Web. De cette manière, on peut également définir des aspects spécifiques à appliquer (transformation d’exceptions, génération d’alertes sur certains comportements de l’application, etc.)
Hibernate :
«Je n’ai pas de base de données existante, et mon modèle de données ne sera pas bien complexe. Pourquoi devrais-je gérer mon modèle objet et mon modèle de données séparément et effectuer le mapping à la main, alors qu’ils collent tous les deux à mon modèle conceptuel de données ? De toute façon, je commence par un prototype, on verra pour les performances après.»
– il suffit désormais d’écrire le modèle objet, et Hibernate génère automatique le modèle de données. Reste tout de même à référencer chacun des objets[[une librairie existe pour que la découverte soit automatique comme pour Spring]] à persister dans un fichier de configuration Hibernate. Il n’est donc plus nécessaire de définir pour chaque propriété des objets la colonne associée dans la base de données car Hibernate gère maintenant cela grâce à des conventions de nommage.
Pour conclure
Le principal avantage des frameworks Java face aux frameworks des nouveaux langages (PHP, Python, Ruby, etc.), moins matures, c’est clairement leur caractère éprouvé. Le développement et la prise en main étaient auparavant laborieux, parce que l’étape de configuration était systématiquement longue. Mais maintenant, les frameworks Java fournissent des comportements par défaut en réponse aux besoins les plus simples.
– Le projet peut démarrer rapidement, les premières livraisons sont rapides
– Le projet reste évolutif. Si de nouveaux besoins apparaissent, il reste possible de configurer des comportements différents des comportements par défaut, pour continuer à tirer profit de toutes les fonctionnalités de la plateforme et du langage.
«Java est mort, longue vie à Java !»



