Facebook avec GraphQL ainsi que Netflix avec Falcor cherchent à perfectionner les échanges client-serveur pour remplacer le modèle REST qui manque de capacité à grossir sans faire exploser le coût en performance et en complexité applicative. Quelles approches peuvent remplacer REST ? Est-il pertinent de s’y intéresser dès maintenant ?
Les limites du modèle REST
Lorsqu’on parle de webservices pour les données, on pense aujourd’hui naturellement au modèle d’API REST ou éventuellement à SOAP, qui permettent de parcourir de façon normée les informations dont dispose un serveur à partir d’un client. Si ce modèle a fait ses preuves et est largement utilisé aujourd’hui, il ne vient cependant pas sans défauts.
Ses inconvénients sont l’absence de typage de la donnée, la nécessité de faire plusieurs (au moins deux) aller-retour pour obtenir une information de détail, un surplus de données renvoyé par le serveur par rapport au besoin du client (over-fetching) et le couplage fort entre les versions du serveur et du client.
Je vais détailler ces points dans les paragraphes suivants, si vous êtes déjà convaincus par ces limitations de REST vous pouvez avancer au titre « Penser autrement ».
Concernant le typage des données, rien n’est spécifié dans les normes de mise en place d’une API REST. Le format json ou xml est généralement utilisé pour la présentation mais les données retournées sont généralement non typées et systématiquement sérialisées, donc lues dans un premier temps sous forme de chaîne de caractères. Les objets sérialisés sont ensuite reconvertis dans leur type d’origine (date, entier, nombre flottant, objet métier spécifique).
Chacune de ces transformations est une source d’erreur possible car en fonction des technologies utilisées et des configurations de localisation, le format de sérialisation pour un même type pourra être différent d’un serveur à l’autre ou d’un client à l’autre. Au sein d’une même application client, il n’est pas rare non plus de voir la même information transformée avec des algorithmes différents à plusieurs endroits du code, car réalisés par des développeurs différents ou à des moments différents dans le développement de l’application.
Erreurs fréquentes :
- format de date anglais/français,
- utilisation de la virgule au lieu du point pour séparer la partie entière et la partie décimale d’un nombre,
- calcul d’arrondi différent en fonction du langage utilisé,
- transtypage automatique d’une chaîne en nombre,
- mauvaise assomption du type de donnée lue par le développeur par manque de documentation.
L’autre inconvénient est la nécessité de faire plusieurs aller-retours. Le modèle REST prévoit en effet d’avoir une URL pour récupérer la liste des objets disponibles (possiblement filtrés en fonction des paramètres d’URL) et qui consiste en une liste d’identifiants. Ensuite, une autre URL permet de venir lire l’ensemble des informations de chacun de ces objets en ré-utilisant l’identifiant obtenu précédemment. Cela nécessite donc, côté client, de devoir stocker de manière temporaire les identifiants à requêter, puis de boucler sur l’appel d’URL par identifiant pour récupérer l’ensemble des informations nécessaires.
On récupérera d’ailleurs aussi des informations inutiles : l’API REST renvoie toutes les informations à disposition, peu importe le besoin réel du client, gonflant inutilement la quantité de données transférée sur le réseau.
Il est bien sûr possible d’optimiser les requêtes fréquemment utilisées et de proposer au niveau du serveur des URLs spécifiques qui retournent directement un ensemble de résultats agrégés, néanmoins tous ces services supplémentaires créés pour des besoins spécifiques sont autant d’éléments à maintenir au fur et à mesure que l’application évolue, créant ainsi une complexité de plus en plus grande avec l’extension de l’application.
De plus, à chaque nouvelle évolution de l’application on voudra créer une nouvelle version de l’API REST. Pourquoi ? Imaginez qu’un nouveau champ est créé dans une V2 de l’application pour compléter un objet existant, les clients V1 recevront de la part du webservice une nouvelle information qui n’était pas présente auparavant. Deux solutions :
- on crée une API V2 au niveau du serveur de tel sorte que les clients V1 continuent d’utiliser l’API V1 sans changement, et que les clients V2 utilisent la nouvelle API V2 ;
- le client V1 peut avoir été prévu pour lire des flux de données s’ils évoluent. Même ainsi, le client V1 devra être re-testé pour s’assurer qu’il est toujours compatible avec les évolutions.
Dans tous les cas, la problématique de maintenance ira en se complexifiant avec le nombre de versions d’API ou de client, pouvant même arriver au stade où il sera nécessaire de déprécier les premières versions du client et d’arrêter leur support, ce qui risquera d’entraîner la perte d’utilisateurs.
Le modèle REST présente donc des inconvénients de part sa conception. Certains problèmes peuvent être minimisés par une implémentation de qualité (librairies assurant la cohérence de la sérialisation, méthodologies de travail rigoureuses) mais le modèle n’est pas conçu pour permettre à l’application de grossir sans une augmentation importante du coût.
Penser autrement les échanges
Dans un monde idéal, on voudrait une application qui puisse grossir sans remettre en cause l’existant :
- un même serveur qui puisse évoluer en restant compatible avec toutes les versions du client ;
- un serveur qui puisse retourner toutes les informations nécessaires en un minimum d’aller-retour ;
- un serveur qui ne retourne que les informations strictement nécessaires ;
- une référence concernant le typage des données échangées, qui soit partagée entre le serveur et le client.
Comme nous sommes exigeants, et que nous n’avons pas envie de refaire tout l’existant parce que c’est la mode, ce système d’échange de données devra pouvoir s’intégrer dans une application existante en parallèle de l’API REST déjà en place.
On dirait une liste au Père Noël, mais c’est plutôt vers Netflix et Facebook que nous allons nous tourner !
L’approche de Falcor
Falcor est un middleware conçu par Netflix,
et qui nous propose de penser notre API comme un objet JSON en fournissant des facilités de lecture de l’objet côté client, et des outils pour faire correspondre des sources des données variées aux nœuds du JSON côté serveur.
Côté serveur
Côté serveur, on définit un arbre de données au format JSON : le JSON Graph. Puis on implémente des routeurs spécifiques pour aller chercher (en base, sur un autre WS, dans un fichier, autre source de donnée) les informations correspondant au nœud de l’arbre JSON requêté.
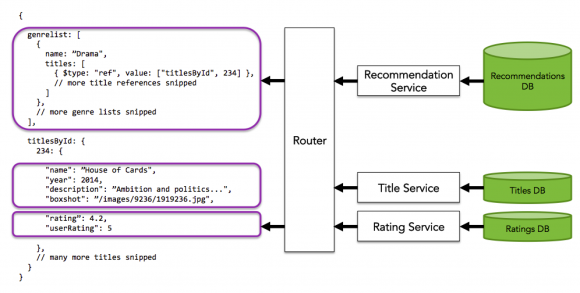
Source : Site officiel de Falcor

Source : Site officiel de Falcor

Source : Site officiel de Falcor
Côté client
Côté client c’est un pattern appelé « Async MVC » qui est recommandé : la vue demande au contrôleur de façon asynchrone les informations dont elle a besoin. Dès qu’elles sont récupérées auprès du serveur, elles sont injectées dans la vue. Ces informations sont requêtées en suivant la définition du JSON Graph déclaré au niveau du serveur.
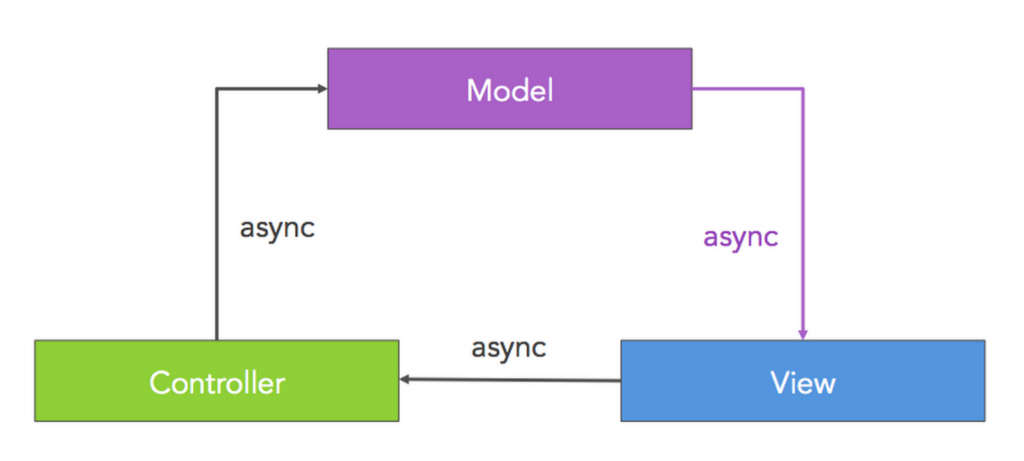
Source : Site officiel de Falcor
Source : Site officiel de Falcor
Source : Site officiel de Falcor
Trois opérations sont supportées côté client sur les données : get, set et call.
getretourne un ensemble de données à partir d’un chemin. Exemple : « titre, date de sortie, URL de l’image des 5 premiers éléments du noeuds sortiesCinema » renverra les fragments du graphe correspond à ces données uniquement.set, de la même façon, demande une modification d’une donnée à l’emplacement décrit par un chemin.callquant à lui est utilisé pour appeler des fonctions. En effet JSON Graph, contrairement à un objet JSON classique, peut porter des fonctions qui seront appelées pour certaines opérations comme les ajouts ou les suppressions.
Intérêt
L’avantage de cette approche est qu’elle est complètement déclarative. Le client n’a pas besoin de savoir comment il doit obtenir l’information (ex : charger la liste d’objets puis charger chaque objet et enfin ne garder que certaines propriétés) mais simplement de décrire l’information dont il a besoin (ex : charger les propriétés x et z des 10 premiers objets du nœud n).
De plus, certaines fonctionnalités sont embarquées avec la bibliothèque :
- Gestion du cache côté client : si les informations demandées ont déjà été récupérées, la vue sera affichée à partir des données en cache plutôt que de requêter à nouveau le serveur.
- Agrégation de requêtes : si plusieurs petites requêtes sont réalisées par le client, une seule requête globale est envoyée au serveur. Par exemple, si la vue demande les informations de film1, film2 et film3, une seule requête film avec comme condition l’identifiant égal à 1, 2 ou 3 sera envoyée au serveur.
- Élimination des doublons : si la même information est requêtée plusieurs fois par la vue, les requêtes doublons sont ignorées.
- Diminution de la taille du code source liée aux appels ajax : Falcor permet de réduire grandement le code réseau et ainsi de le rendre plus maintenable.
L’approche de GraphQL
C’est pour adresser les mêmes problématiques que Facebook a créé GraphQL et son approche, bien que similaire à celle de Falcor, se démarque sur certains points.
Tout d’abord Falcor est une bibliothèque qu’on utilise en l’état avec sa documentation, alors que GraphQL est une spécification. Cela veut dire que n’importe qui peut programmer un serveur respectant les spécifications GraphQL et se rendre compatible avec le système. Une implémentation de référence en JS est heureusement proposée par Facebook, mais il n’est pas difficile d’en trouver pour d’autres langages.
Ensuite, GraphQL est beaucoup plus puissant : là où Falcor est conçu pour récupérer des données, GraphQL est conçu pour requêter des données. Par exemple, GraphQL est capable de requêter un nombre inconnu d’éléments et d’y appliquer des conditions et filtres, alors que Falcor est limité à la lecture d’un nombre fini d’éléments.
En revanche, cette puissance a un coût : celui de la complexité. Concevoir un serveur GraphQL est beaucoup plus ardu. Il faut vraiment avoir besoin de la souplesse qu’il offre sans quoi le temps passé pour le mettre en œuvre, par rapport à un serveur Falcor, ne sera jamais rentabilisé.
Concrètement, le fonctionnement est très proche de celui de Falcor, sauf qu’au delà de faire correspondre un nœud avec une donnée, il faut également faire correspondre les options de requêtes GraphQL (filtres, tris, etc.) pour exécuter cette transformation sur la source de donnée (ex: paramètres de requête SQL, paramètres d’URL) ou dans la fonction de récupération de la donnée.
Au niveau du typage des données par contre, GraphQL impose l’utilisation d’une référence de définition des formats de données, côté serveur. Ce référentiel assure à la fois au client (qui peut requêter ce référentiel) et au serveur de savoir décoder les données dans le même format.
Là où Falcor dispose de trois opérations get, set et call, GraphQL ne dispose que de get et set. Néanmoins le langage de requête étant plus riche, les actions d’ajout et suppression pourront être implémentées au niveau de l’opérations set.
Synthèse
| Fonctionnalité | GraphQL | Falcor |
|---|---|---|
| L’évolution du modèle de données ne remet pas en cause les anciennes versions du client ? | Vrai si le modèle GraghQL reste compatible, c’est à dire que si on a uniquement des ajouts au modèle de données. Les cas de suppression/modification peuvent être gérés côté serveur uniquement en dépréciant (mais en conservant) les éléments des précédentes versions.
Faux dans les cas de modification ou de suppression complète de nœuds au graphe. | Vrai si le modèle JSON Graph reste compatible, c’est à dire si on a uniquement des ajouts au modèle de données. Les cas de suppression/modification peuvent être gérés côté serveur uniquement en dépréciant (mais en conservant) les éléments des précédentes versions.
Faux dans les cas de modification ou de suppression complète de nœuds au graphe. |
| Un minimum d’aller-retour ? | Vrai, toutes les données peuvent être retournées en une seule requête. | Vrai, la gestion incluse du cache, l’agrégation des requêtes, et l’élimination des doublons limitent de façon automatique le nombre de requêtes. |
| Seules les données nécessaires au client sont retournées ? | Vrai, seules les données demandées sont retournées, dans le format spécifié par la requête. | Vrai, seules les données demandées sont retournées. |
| Une référence unique concernant le typage des données échangées, qui soit partagée entre le serveur et le client ? | Vrai, le serveur détient un référence des types de données sur lequel le client peut s’appuyer pour désérialiser les données de manière fiable. | Plutôt faux, Falcor introduit 3 nouveaux types de données dont le type est transmis explicitement (reference, atom et error). Pour le reste tout est transmis sous forme des types de données supportés par JSON avec les mêmes avantages et inconvénients qu’une utilisation de REST. |
| Peut s’intégrer dans une application existante en parallèle de l’API REST déjà en place ? | Vrai, un serveur GraphQL peut coexister avec une API REST et les services peuvent être migrés au fil de l’eau. | Vrai, un serveur JSON Graph peut coexister avec une API REST et les services peuvent être migrés au fil de l’eau. |
Limitations
Pour GraphQL, de grosses questions se posent encore concernant la sécurité. En effet, comme le client est capable de produire des requêtes (potentiellement récursives), les attaques de type DDOS notamment sont aisées si aucune mécanique de protection n’est mise en place spécifiquement sur le serveur pour bloquer les requêtes dangereuses.
Pour GraphQL comme pour Falcor, la limitation de l’accès aux données (en lecture ou en écriture) par authentification est entièrement laissée au développeur, et aucune bonne pratique concernant la sécurité n’ayant encore percée, il convient de bien penser et comprendre le fonctionnement du serveur et comment protéger ses accès.
GraphQL a été créé par Facebook dans l’optique d’interagir avec React, sa bibliothèque de rendu de DOM en JavaScript. La couche assurant la connexion entre le serveur GraphQL et React est Relay. Si vous souhaitez utiliser GraphQL dans cet optique, alors vous bénéficierez automatiquement des mêmes services qu’avec Falcor (cache client, agrégation de requêtes, élimination des doublons). Si en revanche React ne vous intéresse pas, attendez vous à devoir développer vous-même des adaptateurs spécifiques à votre projet côté client pour bénéficier pleinement du modèle GraphQL.
Falcor de son côté est très autonome et fournit ses services sans a priori sur l’architecture qui l’utilise.
Il convient également de souligner que les spécifications de GraphQL d’octobre 2015 sont toujours dans un état working draft et ne sont donc pas stabilisées complètement. Des évolutions conceptuelles bloquantes peuvent survenir et il ne faut pas prévoir de pouvoir faire évoluer sa brique GraphQL sans réécrire du code.
Enfin, mis à part Facebook qui utilise une version interne de GraphQL et qui dispose de beaucoup de ressources pour la faire tourner, et Netflix qui utilise Falcor (a priori dans sa version publique par contre), il existe peu de retour d’expérience sur l’utilisation de ces outils.
Conclusion
Il est important de reconnaître les faiblesses du modèle REST : il est possible de faire mieux en termes de volume de données, de nombre de requêtes, et de complexité applicative pour gérer les appels. GraphQL et Falcor sont des solutions conceptuellement séduisantes et déjà mise en pratique avec succès dans des contextes de production exigeants (Facebook et Netflix). Il ne faut pas cependant crier victoire trop tôt : Facebook et Netflix ont les moyens d’investir dans le développement et la maintenance de ces outils et le coût actuel pour bénéficier des avantages de l’un ou de l’autre n’est pas forcément à la portée de tout le monde. Oui, leur approche est performante. Oui, leur approche est élégante. Mais le manque de retour d’expérience rend l’utilisation de ces outils risquée.
On utilisera donc l’un ou l’autre :
- dans des applications aux besoins complexes et exigeants en face desquels on souhaite mettre les moyens nécessaires ;
- pour des projets expérimentaux, non critiques, où les risques sont modérés ;
- ou en tant qu’évolution d’un existant pour se faire la main progressivement et appréhender la pertinence de l’approche petit à petit.
L’idée fonctionne et l’implémentation gagnera en fiabilité avec le temps : le déclin du modèle REST parait déjà amorcé.
Sources et références
- Declarative data fetching
- Falcor
- Netflix jsongraph
- Visual relay explanations
- GraphQL introduction
- Différences entre Falcor et GraphQL par l’architecte derrière Falcor
- GraphQL + sécurité
- Falcor + sécurité



