Dans ce troisième article de la série consacrée aux failles applicatives, j’aborde les failles CSRF au travers de l’OWASP. Vous découvrirez ces failles et apprendrez à les détecter. Vous verrez enfin les moyens de vous en prémunir.
Introduction
L’objet de l’attaque CSRF est de forcer des utilisateurs à exécuter une ou plusieurs requêtes non désirées sur un site donné, forgées par un utilisateur malintentionné. La victime choisie aura les privilèges nécessaires à l’exécution de la requête, voire une session encore active.
Forger une requête reviens à créer / falsifier une requête HTTP (par le biais d’une URL ou d’un formulaire principalement) pointant sur une action précise interne au site et néfaste pour la victime.
Concrètement, une ressource vulnérable aux attaques CSRF est représentée par toutes ressources disponibles directement ET sans étape intermédiaire (ex: génération de clé/jeton d’autorisation d’accès) sur un SI.
Rappel
L’OWASP (Open Web Application Security Project) dispose d’un projet de classification des failles les plus couramment utilisées par des utilisateurs malintentionnés sur Internet. Ce document est accompagné d’une qualification des menaces listées et d’une explication sur l’exploitation.
Ce projet se nomme le “Top Ten » (et sort chaque année si le classement évolue), et est disponible à cette adresse : https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project
En 2010, les failles de type CSRF sont classées à la 5ème position, tandis que cette année elles arrivent en 8ème position.
Qualification de la menace
On pourrait presque qualifier la faille CSRF de “sur-couche” ou “vecteur d’aggravation”, car elle aura un impact seulement si une autre vulnérabilité est présente dans le SI (le vecteur d’attaque est souvent soit une XSS soit du phishing).
Remarque : Une attaque CSRF sera d’autant plus dangereuse qu’il y a de fonctionnalités vulnérables exposées par le SI.
|
Agent de menace |
_ |
Considérez n’importe quel individu pouvant tromper vos utilisateurs en soumettant une requête à votre site. N’importe quel site ou autre source HTML auxquels vos utilisateurs pourraient accéder. |
|
Vecteur d’attaque |
Facilité Moyenne |
L’attaquant forge une requête HTTP et amène une victime à la soumettre via une balise d’image, une XSS, du phishing, ou de nombreuses autres techniques. Si l’utilisateur est authentifié, l’attaque est un succès. |
|
Vraisemblance de la vulnérabilité |
Répandue |
CSRF prend avantage des applications web qui permettent aux attaquants de prédire les détails d’une action particulière. |
|
Détection de la vulnérabilité |
Facile |
Les attaquants peuvent créer des pages web malicieuses qui génèrent des requêtes forgées, qui ne sont pas distinguables des légitimes. La détection des CSRF est assez facile via un test de pénétration ou analyse de code. |
|
Impact technique |
Moyen |
Les attaquants peuvent faire exécuter n’importe quelle type de fonctionnalité présente dans le SI, à laquelle la victime aurait accès. |
|
Impact métier |
_ |
Tout dépend de l’action exécutée. |
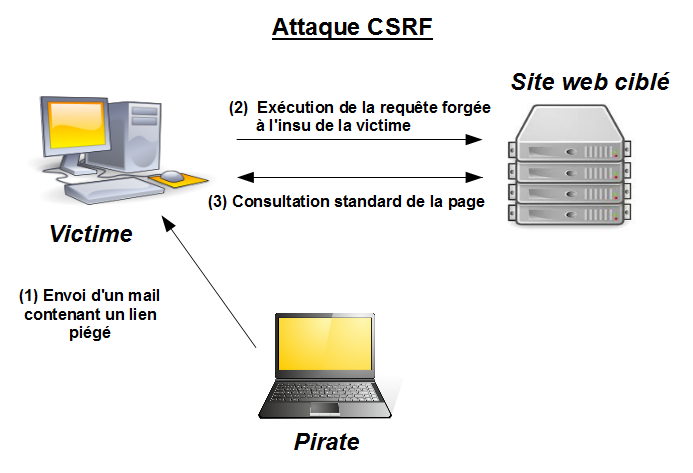


Exemples d’attaques
Cas fictifs
Service bancaire
Imaginez un bouton sur votre site de banque en ligne permettant d’effectuer un virement sur un compte extérieur ayant pour URL :
http://www.mabanque.com/transaction.php?dest=ID12345&somme=2000
Où le paramètre « dest » est l’identifiant du destinataire de la transaction et « somme », le montant de la transaction. Admettons ensuite que Mme Lambda soit allée voir ses relevés bancaires et que sa session soit toujours active. Imaginons ensuite qu’un utilisateur malveillant, connaissant la victime, ait décidé de lui envoyer un mail (en usurpant l’adresse e-mail d’un de ses proches).
L’e-mail contiendrait un lien vers cette action et avec pour destinataire son identifiant de compte. Si Mme Lambda clique sur le lien, alors la transaction sera effectuée contre son gré.
Si cette attaque est couplée d’une attaque XSS (en utilisant par exemple une balise img) sur le site bancaire, alors chaque utilisateur connecté sur le site sera victime de ce détournement de fonds.
Webmail
Même exemple pour un Webmail, avec un lien permettant de supprimer vos e-mails.
Bot
Un robot qui a pour objectif de polluer votre base de données en “spammant”. Le robot récupèrerait votre page une fois, analyserait les champs de formulaire, et enverrait une multitude de requêtes avec des valeurs quelconques.
Social Network
De nos jours, tout le monde connaît les boutons de partage liés aux réseaux sociaux (tel que les boutons « J’aime » de Facebook, “+1” de Google+, etc). Ces boutons permettent d’ajouter une
page à nos favoris, sauf qu’ici l’utilisateur est conscient de l’action effectuée en cliquant dessus.
Or, il est possible pour un utilisateur malintentionné de faire dériver le comportement initial de ces boutons pour porter atteinte à la victime via des techniques dîtes de “Phishing” ou “Clickjacking” :
Cas n°1
Imaginons qu’un utilisateur malveillant conserve le rendu visuel de ce bouton mais en changeant son comportement (ex: modifiction de l’URL), un utilisateur habitué pourrait cliquer instinctivement (par habitude) dessus et exécuterai l’action forgée par le pirate (ex: redirection sur un site piégé, exploitation de la session active de la victime, etc.).
Cas n°2
Ce bouton pourrait être camouflé (sans changer son URL) par dessus un élément banal et cliquable sur un site vulnérable. Lorsque l’utilisateur pensera cliquer sur un élément souhaité, il cliquera en fait sur l’élément caché par le pirate et exécutera par conséquent l’action forgée. Ce camouflage est possible par exemple via la directive CSS : “opacity: 0.001;”, l’élément caché sera invisible pour une personne, mais la propagation des évènements au sein du DOM restera identique.
Anecdote : Une bien mauvaise blague serait de mettre en pratique cette technique sur un site de vidéos douteuses en streaming à la place du bouton lecture… L’impact ici est un préjudice moral. Ce genre de dérive à été pointée du doigt dans un article du site “PcInpact”, cf : http://www.pcinpact.com/news/62398-bouton-jaime-like-facebook-cdrole.htm ou encore :
http://www.mycommunitymanager.fr/arretez-de-vous-faire-avoir-sur-facebook/
Cas pratique
Site éditorial
Prenons pour exemple un site éditorial lambda disposant :
– D’une gestion des commentaires enrichie, autorisant certains éléments HTML tels que les paragraphes, les sauts de ligne, les images, etc.
– D’une interface d’administration des commentaires (ou chaque commentaire est affiché directement une fois connecté sur cette interface)
– D’une URL de déconnexion du type : http://www.foobar.net/logout.php
Il suffirait que l’utilisateur malveillant injecte dans son commentaire une image qui pointerait vers l’URL de déconnexion pour empêcher toute administration du site : l’utilisateur serait déconnecté tout de suite après s’être connecté.
Exemple de commentaire :
Ceci est une attaque CSRF
Remarque : Il s’agit ici d’une attaque CSRF qui passe par une “stored XSS” (ou XSS stockée).
Comment se protéger ?
Le projet OWASP nous propose deux approches pour se prémunir des attaques CSRF : https://www.owasp.org/index.php/Cross-Site_Request_Forgery_%28CSRF%29_Prevention_Cheat_Sheet
La 1ère solution est basée sur le “design pattern” (ou patron de conception) : “Synchonizer Token Pattern” (cf : http://www.corej2eepatterns.com/Design/PresoDesign.htm), cette solution requiert la session d’un utilisateur courant. Il s’agit de la solution préconisée.
Dans un deuxième temps vous seront proposées plusieurs autres solutions ou visions du problèmes dans le cas d’une application “sans-état”, c’est-à-dire qu’aucun paramètre n’est conservé depuis le serveur pour le client (ne nécessite pas de session). La plupart de ces solutions ne vous protègeront pas intégralement.
Protection CSRF en mode Stateful
Synchronizer Token Pattern
Il s’agit d’ajouter un paramètre obligatoire correspondant à un identifiant d’accès unique et non prédictible, regénéré pour chaque action utilisateur et par utilisateur (le plus efficace), ou pour chaque session (le moins efficace). Cet identifiant d’accès (ou “laisser-passer”) est nommé “jeton CSRF”. Ce mécanisme doit être implémenté sur chaque action qui dépend de l’utilisateur qui l’exécute (déconnexion, modification/suppression de données en BDD, etc.) et doit avoir une durée de validité limitée dans le temps.
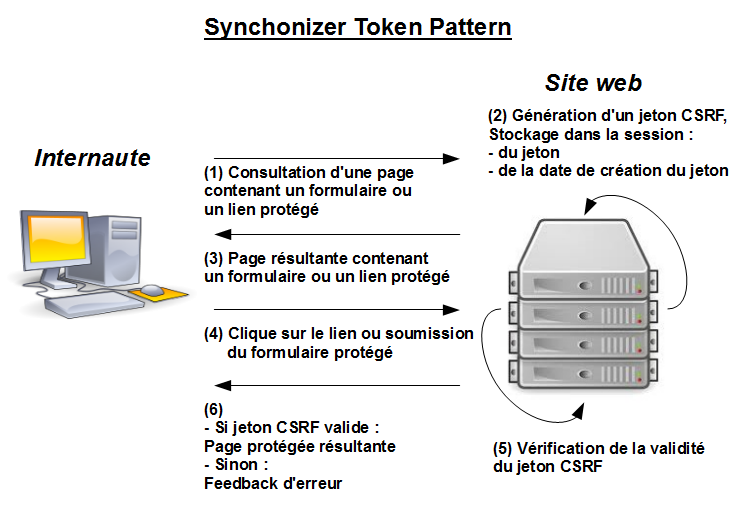
Concrètement, lorsque l’utilisateur appelle une page, le serveur génère un jeton CSRF unique et non prédictible, et le stock en session (ainsi que l’IP publique depuis laquelle le client à interrogé le serveur ou tout autre discriminant lié à l’identité de l’internaute. Bien qu’optionnelle, c’est une condition supplémentaire pour accroître la sécurité en s’assurant que le jeton à été émis par la bonne personne).
– Si c’est un formulaire, le jeton CSRF est inséré dans le corps du formulaire (dans un input de type hidden). Lorsque l’utilisateur validera ce formulaire, le jeton CSRF sera renvoyé au serveur qui vérifiera sa validité et le périmera, un jeton invalide empêchera le traitement des données envoyées par le formulaire.
– Si ce n’est pas un formulaire (accès à une page privée par exemple), c’est lors de la génération du lien vers l’action que le jeton sera généré, stocké en session et ajouté dans l’URL en tant que paramètre. Sans jeton, la ressource ne sera donc pas accessible.
Grâce à ce mécanisme, il devient inutile pour un utilisateur malveillant de forger des liens pour piéger quelqu’un, car le jeton CSRF change et est propre à un utilisateur. De plus, cela permet aussi de protéger contre le spam, dans le cas où un robot ne récupèrerait qu’une seule fois la page (il ne récupèrerait donc le jeton CSRF qu’une fois et celui-ci sera périmé après la première tentative de spam).
Note : Autre idée intéressante pour se prémunir contre une grande majorité de robots, il suffirait d’ajouter un champ factice dans chaque formulaire. Ce champ, pour que le formulaire soit valide, doit toujours être vide. Il pourrait avoir pour label : « À ne pas remplir » et serait caché en CSS. Un utilisateur non-averti, avec le CSS activé, ne pourrait pas voir ce champ, il ne le remplirait donc pas. Si le CSS est désactivé, le label aura un rôle informatif. Un robot qui analyse la page ne pourrait savoir qu’il s’agit d’un champ factice, il le remplirait donc avant de soumettre le formulaire. Autre avantage en terme d’accessibilité grâce à cette solution : les logiciels de lecture de site web spécialisés pour les personnes aveugles liraient le label du champ du formulaire permettant de prévenir l’utilisateur.
Double Submit Pattern
Toutefois, si notre application est vulnérable aux attaques de type XSS, il serait possible pour un attaquant de voler notre cookie de session puis d’exécuter rapidement une action pour “consommer” le jeton CSRF avant l’utilisateur initial (soit une “timing-attack”).
Pour éviter ce type de dérive intervient un dernier concept, celui de “double soumission” (ou “double submit pattern”) qui consiste à complexifier la solution précédente.
En plus d’envoyer le jeton CSRF via un paramètre dans la requête HTTP, il faudra ajouter cette notion dans un cookie avec impérativement l’attribut “HTTPOnly“.
Ajouter ce dernier attribut permet d’empêcher Javascript d’accéder au cookie et de récupérer son contenu (via la directive “document.cookie”) pour l’envoyer sur un serveur pirate.
Ce cookie sera regénéré à chaque fois qu’un jeton sera créé et, idéalement, il devrait s’agir du cookie de session qui contiendra par exemple l’identifiant de session concaténé au jeton CSRF.
Pour résumer, pour un utilisateur spécifique et pour chaque action seront générés :
- un jeton CSRF
- un nouveau cookie
Les deux seront validés côté serveur. Si l’un des deux n’est pas envoyé ou invalide, l’utilisateur ne pourra pas accéder à la ressource. Cette solution complète est celle préconisée !
Mauvaises pratiques
- Envoyer au client le jeton CSRF dans les URLs (en GET)
Cela faciliterait sa récupération, si un administrateur réseau malveillant venait à sniffer le réseau avec des outils comme Wireshark, Ethercap, tcpdump, etc. Ensuite, il est préférable que le nom du paramètre du jeton CSRF ne soit pas explicite, et ce afin de complexifier sa récupération si un robot venait à percer le code d’une page. Toutefois, mieux vaut un jeton CSRF dans l’URL qu’aucune protection.
- Mettre en cache de manière globale le contenu HTML (formulaires et/ou liens) contenant un jeton CSRF
Et ceci car ce contenu HTML est spécifique à un utilisateur donné ! La première fois que la page est affichée, le contenu HTML généré est stocké dans le cache avec le jeton CSRF de l’utilisateur en cours. Si un autre utilisateur vient après, la page venant du cache sera affichée avec le jeton CSRF du 1er utilisateur. En soumettant le formulaire ou en cliquant sur un lien protégé, le jeton ne correspond pas et une erreur est levée. Seuls les formulaires qui ne dépendent pas de l’utilisateur qui les rempliront doivent être mis en cache de manière globale.
Protection CSRF en mode Stateless
D’autres petits mécanismes permettent de se prémunir de cette vulnérabilité (de manière plus ou moins complète) comme :
Vérifier le header HTTP Referer
Autant il est possible de facilement usurper ce header via différents outils (client http, web-proxy, navigateur, etc.) autant il est impossible de le faire dans le cas d’une attaque CSRF standard (vecteur de type XSS ou phishing). C’est pourquoi vérifier la valeur de ce header peut aider à se prémunir de ces attaques. Cette solution n’est toutefois pas suffisante dans le cas où un bot de type client HTTP appellerait directement une ressource spécifique et vulnérable aux CSRF.
De plus, cette solution ne fonctionnera carrément pas dans plusieurs cas (cf: http://en.wikipedia.org/wiki/HTTP_referer#Referer_hiding) :
- Le header Referer n’est pas envoyé dans un contexte HTTPS pour des raisons de sécurité
- Depuis HTML5, l’attribut HTML rel = « noreferrer » d’une balise <a> permet de demander au navigateur de ne pas envoyer le Referer si l’internaute clique sur le lien.
Vérifier le header HTTP Origin
Ce header à été implémenté récemment pour se prémunir contre les attaques CSRF et autres attaques types “cross-domain” (cf: https://wiki.mozilla.org/Security/Origin)
Il permet d’empêcher l’accès à une ressource depuis une origine non autorisée.
Un exemple d’implémentation détaillé est disponible dans l’article suivant : http://deadliestwebattacks.com/2013/08/08/and-they-have-a-plan/
Challenge-Response
D’autres solutions alternatives sont possibles, telles que :
- Utilisation de Captcha
- Ré-authenfication
Elles permettent de manière détournée de se prémunir des attaques CSRF mais sont trop intrusives pour l’utilisateur final et nuisent à l’UX.
De plus, si la connexion n’est pas en HTTPS, pousser l’utilisateur à se ré-authentifier n’est pas une bonne pratique, car les identifiants circuleront une fois de plus en clair sur le réseau.
Exemple d’implémentation du token et outil
Framework Symfony 1.X
Dans le framework Symfony en version 1.X, le mécanisme anti-CSRF mis en place est le Synchronizer Token Pattern sans double-submit. Et la solution n’a été implémentée que dans le cadre de formulaire HTML.
Lors de la création d’une application, Symfony génère aléatoirement une passe-phrase secrète modifiable par projet ou par application dans le fichier /apps/%app_name%/config/settings.yml :
all:
.settings:
csrf_secret: XxXxXxXxXxXxXxXxXxXxXxXxXxXxXx
Cette passe-phrase va être concaténée à l’identifiant de session de l’utilisateur et concaténée au nom de la classe du formulaire puis hashée en MD5. Ce hash représente le jeton CSRF final (ce jeton est unique pour un utilisateur donné et pour un formulaire donné) avant d’être stocké dans la session utilisateur ainsi que dans le formulaire (dans un champ input de type hidden).
Ci-joint, le code de la fonction de génération du jeton CSRF de Symfony :
public function getCSRFToken($secret = null)
{
// [...]
return md5($secret.session_id().get_class($this));
}Framework Symfony 2.X
Dans le framework Symfony en version 2.X, le mécanisme anti-CSRF mis en place est le même que Symfony 1.X : “Synchronizer Token Pattern” sans double-submit. L’implémentation diffère toutefois légèrement sur cette nouvelle version du framework.
La génération du token est définie dans la classe “DefaultCsrfProvider” :
public function generateCsrfToken($intention)
{
return sha1($this->secret.$intention.$this->getSessionId());
}Remarque : Le paramètre de la fonction (ou $intention) corresponds à l’identifiant unique de la fonctionnalité qui nécessite et utilise le token généré. Ce paramètre est utilisé pour la génération et la validation du token, par conséquent il ne devra pas être aléatoire !
Par contre, rien de vous empêche d’ajouter d’autres paramètres dynamiques concaténés à $intention pour le rendre moins prédictible et donc plus robuste.
Comme dans Symfony 1.X, un paramètre statique définie dans le fichier “parameters.yml” est utilisé lors de la génération du token (il est spécifique au projet) :
parameters:
secret: my_secret_param_for_csrf_token Magento
Dans cette solution e-commerce implémentée en PHP est utilisé nativement un mécanisme de génération de token CSRF sur l’ensemble des URLs de l’interface d’administration.
Ainsi chaque ressource est protégée contre ce genre d’attaque, mais aucune d’elle n’est accessible directement sans passer par le contrôleur principal.
OWASP CSRF Guard
Le projet OWASP propose des snippets (morceaux de code) pour faciliter l’implémentation de mécanismes anti-CSRF disponibles pour les langages :
- Java : https://www.owasp.org/index.php/Category:OWASP_CSRFGuard_Project
- PHP : https://www.owasp.org/index.php/PHP_CSRF_Guard
- .NET : https://www.owasp.org/index.php/.Net_CSRF_Guard
OWASP Enterprise Security API (OWASP ESAPI)
L’ESAPI est une librairie libre, open-source, qui implémente de nombreux mécanismes de sécurité afin de faciliter le travail d’un développeur averti sur des problématiques de sécurité.
Cette API est disponible dans de nombreuses langues mais c’est en Java qu’elle semble la plus mature (contrairement à son homologue en PHP).
Le projet est disponible à cette adresse : https://www.owasp.org/index.php/Category:OWASP_Enterprise_Security_API#tab=Home
Un exemple d’utilisation de l’API pour la génération de token CSRF en Java est disponible à cette adresse : http://www.jtmelton.com/2010/05/16/the-owasp-top-ten-and-esapi-part-6-cross-site-request-forgery-csrf/
Comment détecter si notre application est vulnérable ?
Comme de nombreux outils dédiés à l’automatisation des tests d’intrusions, le projet OWASP ZAP (Zed Attack Proxy) dispose de détecteurs de dispositif anti-CSRF distingué en deux catégories :
- Mode passif :
Il s’agit d’un filtre passif appliqué sur chaque réponse HTTP. Il vérifie si dans son contenu un formulaire existe avec un champs généré de manière aléatoire lors de chaque appels avec un nouveau contexte (sans conserver la session). - Mode actif :
Un module permet de simplifier la génération de requêtes HTTP d’exploitation d’un CSRF, un exemple d’utilisation est disponible à cette adresse : http://resources.infosecinstitute.com/csrf-proof-of-concept-with-owasp-zap/
L’utilisation de ces outils permet de cibler rapidement (dans l’application auditée) : un formulaire vulnérable aux attaques CSRF, mais ne remplace pas, je trouve, les tests manuels : plus complet, qui ne serait pas limité seulement aux formulaires, qui ne serait pas sujet à de résultats “faux négatif”.
Cet outil est disponible depuis cette adresse : https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project
Remarque : Il ne s’agit pas d’un outil dédié uniquement à la recherche de faille CSRF mais bien d’une solution complète, très utile pour assister le Pentester lors d’un audit.
Références et Webographie
- OWASP Top10 : https://www.owasp.org/index.php/Category:OWASP_Top_Ten_Project
- OWASP CSRF : https://www.owasp.org/index.php/CSRF
- OWASP CSRF Prevention Cheat Sheet: https://www.owasp.org/index.php/Cross-Site_Request_Forgery_%28CSRF%29_Prevention_Cheat_Sheet
- Synchronizer Token Pattern : http://www.corej2eepatterns.com/Design/PresoDesign.htm
- Wikipédia – HTTP Referer – Hiding cases : http://en.wikipedia.org/wiki/HTTP_referer#Referer_hiding
- Wiki Mozilla – Origin HTTP Header : https://wiki.mozilla.org/Security/Origin
- Exemple d’implémentation Origin HTTP Header : http://deadliestwebattacks.com/2013/08/08/and-they-have-a-plan/
- OWASP ESAPI : https://www.owasp.org/index.php/Category:OWASP_Enterprise_Security_API
- OWASP ESAPI, exemple d’implémentation : http://www.jtmelton.com/2010/05/16/the-owasp-top-ten-and-esapi-part-6-cross-site-request-forgery-csrf/
- OWASP ZAP CSRF PoC : http://resources.infosecinstitute.com/csrf-proof-of-concept-with-owasp-zap/
- OWASP ZAP : https://www.owasp.org/index.php/OWASP_Zed_Attack_Proxy_Project



