Le modèle de données relationnel de certaines applications web est parfois si complexe que les performances se dégradent rapidement en cas d’affluence. Pour répondre à cette problématique, nous abordons dans cet article la mise en oeuvre d’une solution moderne d’indexation : Elasticsearch.
Dans le cas de sites e-commerce par exemple, les accès au moteur de recherche ou à une fiche produit peuvent engendrer un grand nombre de requêtes SQL. Si les données sont modifiées régulièrement en « back office », il est difficile de mettre en place une stratégie de cache efficace et l’exploitation des plate-formes d’hébergement est fastidieuse. Pour régler ce problème, une solution désormais répandue consiste à exposer un index. Cet index stocke les informations nécessaires au « front » et autorise des temps d’accès réduits pour les clients du site.
Dans cet article, nous allons mettre en place la solution d’indexation Elasticsearch. Il s’agit d’une solution open source en Java qui expose une API JSON au dessus d’Apache Lucene.
Un exemple d’architecture intégrant Elasticsearch
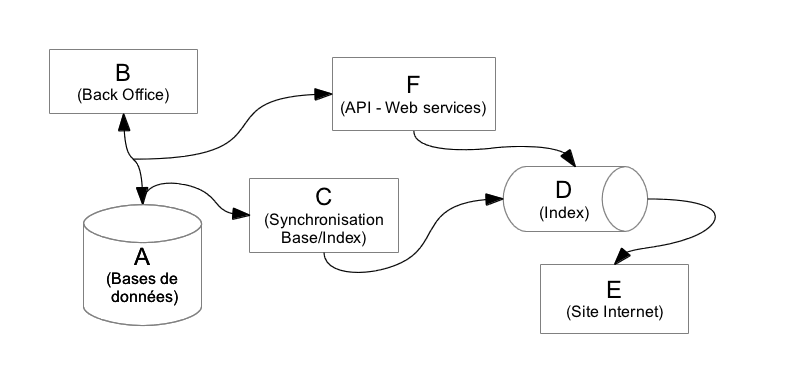
Imaginons des bases de données (A) éditées et interrogées par des applications du « back office » (B). Une application (C) permet de transférer les données vers l’index (D) qui sera utilisé par le site Internet (E) exposé au public. Idéalement, une API (F) expose des web services pour que chaque action dans les « back office » implique une mise à jour en temps réel de l’index. Il est également possible de déployer une solution « asynchrone » en s’appuyant sur des « workers » chargés de mettre à jour l’index suite à des déclenchements de « triggers » sur les tables des bases de données concernées par l’indexation.
Par rapport au modèle relationnel, le schéma d’Elasticsearch est ouvert, orienté document. Un « mapping » des données (lien entre la définition des tables SQL et la définition des données contenues dans l’index) permet de conserver la cohérence des données. De nouvelles fonctionnalités de recherche sont accessibles (facettes, optimisation, …). Le paramétrage de la solution est simple et il sera facile de déployer de nouveaux « cluster » si les performances venaient à se dégrader.
Exemple de déploiement
Pour illustrer le potentiel de la solution, nous mettons en place un serveur Linux avec Apache, PHP, Java, PostgreSQL et Elasticsearch. Ce choix est arbitraire car Elasticsearch peut-être utilisé dans divers environnements.
Le serveur virtuel (sous Debian 6.0)
Pour mettre en place notre prototype de test, nous utilisons Vagrant. Il s’agit d’un projet récent qui s’appuie sur VirtualBox. Il permet de déployer des machines virtuelles sans se préoccuper des configurations « bas niveau ». Le projet est très bien documenté et quel que soit l’environnement (Linux, Mac OS, Windows) très simple à installer. Voici un exemple sous Linux :
cd /opt/
sudo -s
# Téléchargement de Vagrant
wget http://files.vagrantup.com/packages/41445466ee4d376601fd8d0c6a5e3af61d32f131/vagrant_1.0.2_x86_64.deb
# Installation de Vagrant
dpkg -i vagrant_1.0.2_x86_64.deb
./vagrant/bin/vagrant -v
ln -s /opt/vagrant/bin/vagrant /usr/bin/vagrant
# Téléchargement de VirtualBox
wget http://download.virtualbox.org/virtualbox/4.1.12/virtualbox-4.1_4.1.12-77245~Debian~squeeze_amd64.deb
# Installation de VirtualBox
dpkg -i virtualbox-4.1_4.1.12-77245~Debian~squeeze_amd64.deb
exit && cd
vagrant box add base http://files.vagrantup.com/lucid32.box # longuet
mkdir elasticsearch && cd elasticsearch && vagrant init
Nous utiliserons le serveur web d’Apache pour servir du contenu sur le port 80. Nous allons donc rediriger un port local vers le port 80 de la machine virtuelle en éditant le fichier de configuration créé lors du lancement de la commande vagrant init :
vi -c 32 Vagrantfile
config.vm.forward_port 80, 8080 # Enlever les commentaires de cette ligne
vagrant up
vagrant sshAprès quelques minutes d’attente, la machine virtuelle est démarrée et nous pouvons configurer le serveur. Nous sommes dans un environnement Linux « vierge » qui va nous permettre d’installer la solution.
sudo -s
apt-get update
apt-get upgrade
apt-get install php5-cli php5-pgsql php5-xsl php-apc php5-curl git-core subversion apache2 libapache2-mod-php5 curl postgresql openjdk-6-jreCette opération est longue, mais une fois ces paquets installés, vous devriez pouvoir accéder au serveur web de la machine virtuelle depuis la machine hôte en spécifiant le port dans votre navigateur.
Configuration de la base de données
su postgres
# psql
# alter role postgres with encrypted password 's3cr3t';
# q
exit
exit
cdL’application PHP
Nous utiliserons Elasticsearch dans le cadre d’un moteur de recherche développé dans une application Symfony1 disponible sur Github.
mkdir elasticsearch
cd elasticsearch
git clone https://github.com/cleverage/demo-elasticsearch src
cd src/
git submodule update --init
sudo ln -s /home/vagrant/elasticsearch/src/php/symfony1/web /var/www/elasticsearch
mkdir php/symfony1/log
chmod 777 php/symfony1/logLes données
Pour faire nos tests, nous allons utiliser le modèle de données basique suivant :
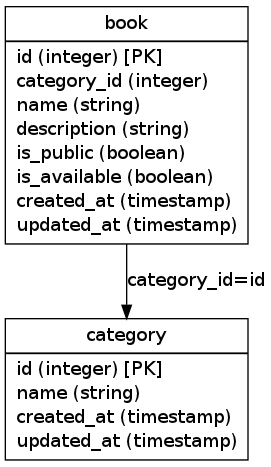
Nous pouvons charger le modèle de données et des « fixtures » en base :
php php/symfony1/symfony doctrine:build --all --and-load
php php/symfony1/symfony doctrine:init-data # charge 10000 enregistrements dans la base pendant quelques minutesElasticsearch
Dans une configuration simple, Elasticsearch est très simple à installer. Il suffit de le télécharger, le décompresser dans un répertoire de votre choix et de lancer la commande de démarrage :
cd ..
mkdir opt
cd opt
wget https://github.com/downloads/elasticsearch/elasticsearch/elasticsearch-0.19.2.tar.gz
tar zxvf elasticsearch-0.19.2.tar.gz
./elasticsearch-0.19.2/bin/elasticsearch
cd ../srcPour « communiquer » avec Elasticsearch depuis PHP, nous utilisons Elastica. C’est une bibliothèque open source compatible avec Symfony1 (< PHP 5.3). Il existe de nombreux clients notamment pour PHP5.3 et quel que soit le langage que vous utilisez.
L’initialisation se déroule en trois étapes :
- création de l’index ;
- mapping des données ;
- insertion des données.
php php/symfony1/symfony search:create-index # Création de l'index
php php/symfony1/symfony search:init-mapping # Correspondance entre les champs de la base de données et l'index
php php/symfony1/symfony search:init-data # Chargement des données dans ElasticsearchVoilà, l’application doit être fonctionnelle et accessible sur votre navigateur. L’exemple déployé est très simple mais il permet de démontrer la facilité d’utilisation de composants open source pour mettre en place une solution d’indexation.
Résultats
Nous sommes évidemment loin des conditions de production mais les résultats sont quand même intéressants : moins de 200 ms pour interroger les 10 000 enregistrements de notre index et connaître leur répartition par catégorie (recherche à facettes).
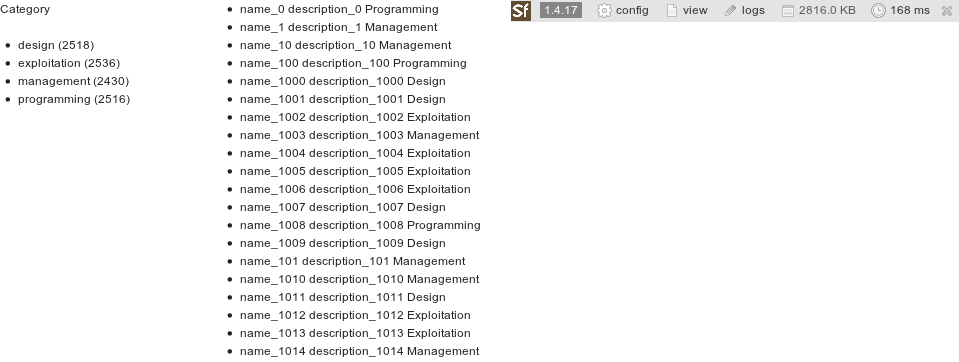
Si nous augmentons le nombre d’enregistrements à plus de 80 000, la gestion interne du cache par Elasticsearch permet de conserver des temps de réponse au-dessous de 200 ms. A titre de comparaison, la même requête réalisée avec un client PostgreSql prend plus de 300 ms.
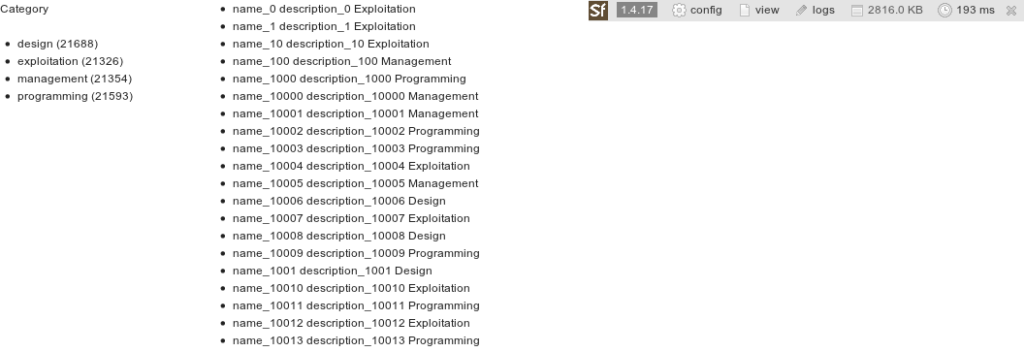
Cet exemple ne fait que survoler les aspects techniques de la mise en place d’Elasticsearch. Si vous voulez aller plus loin, les possibilités d’Elasticsearch sont illimitées. Les tests distribués avec le projet PHP Elastica permettent par exemple de voir de nouveaux cas d’utilisation.
Conclusion
Elasticsearch est une solution très riche. La documentation est assez bien faite. Même si le format court des chapitres peut être un peu déroutant au début, elle permet d’explorer les différentes fonctionnalités et de trouver des réponses à des questions sur une implémentation particulière (objets imbriqués, percolation, …).
A première vue, les développeurs familiers des bases de données relationnelles seront peut-être déçus ne de pas disposer d’équivalent à l’instruction SQL « GROUP BY » pour manipuler les données de l’index Elasticsearch. Ce problème a déjà été soulevé et peut être contourné facilement. L’implémentation de cette fonctionnalité est très attendue par les utilisateurs …
Parfois la richesse de l’API d’Elasticsearch est un peu déroutante mais l’outil possède de nombreux avantages : open source, schéma de définition des données libre et ouvert (NoSQL), API JSON, paramétrage de base simple, scalabilité, ergonomie de recherche … Un projet en devenir à utiliser sans attendre.



