CQRS (Command and Query Responsibility Segregation) est un modèle d’architecture plutôt récent et que l’on croise donc assez rarement dans les phases de conception. Pourtant, ce type d’architecture innovant peut rendre bien des services, surtout si vous pensez déployer votre application sur une infrastructure distribuée.
CQRS, définition
CQRS est un modèle d’architecture système qui sépare la partie lecture de données (query) de celle qui les modifie (command) de manière à produire un système extensible, distribuable, et fournir quelques avancées utiles qui rendent la maintenance du système moins pesante.
Comparaison entre une architecture 3 tiers et une architecture CQRS
Pour mieux comprendre l’organisation d’une application basée sur une architecture CQRS, essayons de monter un rapide comparatif entre une architecture 3 tiers classique et une architecture CQRS.
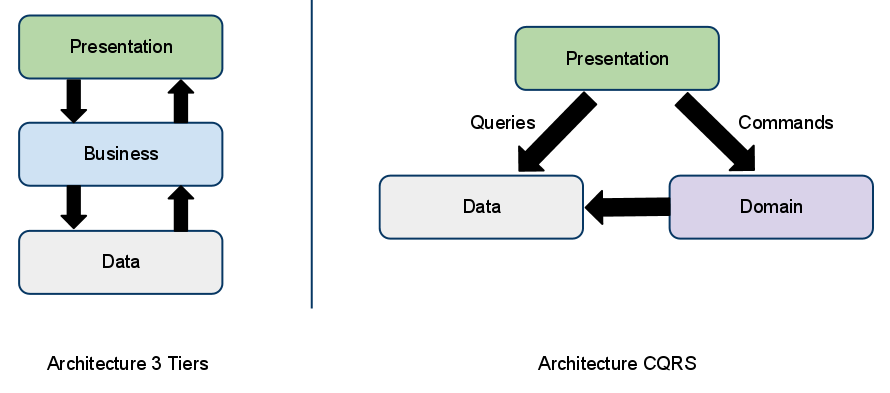
Du côté de l’architecture 3 tiers, les services qui permettant d’accéder aux données se confondent avec ceux qui vont agir sur ces mêmes données. Que vous vouliez lire ou écrire des données, vous traversez les mêmes couches, utilisant parfois les mêmes composants pour ces différents types d’action.
Avec CQRS c’est différent. On sépare volontairement les composants qui vont permettre de requêter les données de ceux qui vont les modifier. Cette séparation, au delà de faciliter l’organisation de l’application, permet de répartir plus facilement les charges si l’on dispose d’une infrastructure distribuée.
CQRS en détails
Au premier abord, l’architecture peut paraître un peu complexe. Pourtant une fois les concepts de base assimilés, le fonctionnement devient beaucoup plus limpide.
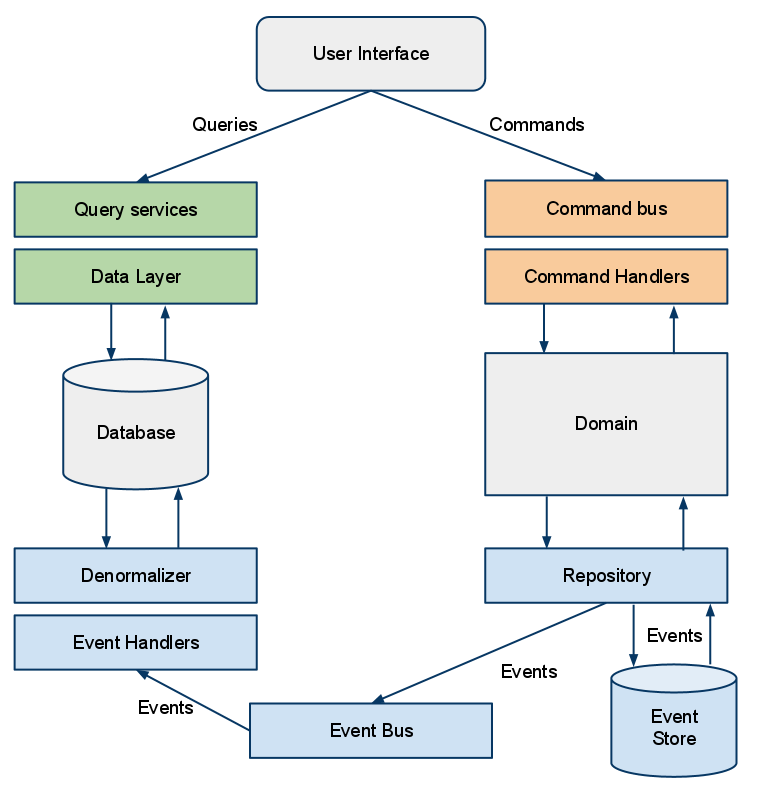
Il serait ambitieux de prétendre couvrir tous les aspects de CQRS en un article tellement ce modèle est riche. Je vais cependant m’attacher à vous présenter les quatre points cruciaux de ce modèle d’architecture.
La couche de lecture des données (Query)
Il s’agit d’une couche qui fonctionne uniquement en lecture seule. Aucune modification n’est apportée aux données. On utilise généralement des objets et tables spécifiques à l’interface utilisateur. Ici un seul objectif : aller le plus vite possible. Les contrôles sont donc réduits au minimum (on ne passe pas par la couche domaine dont on parlera plus tard) et en base de données, les données sont dénormalisées au maximum, quitte à avoir de la redondance. Cette méthode permet de récupérer seulement les données dont on a besoin, sans avoir à parcourir de nombreuses tables au travers desquelles les données seraient éparpillées.
Cette couche est généralement composée de services qui exposent les données et d’interfaces légères qui requêtent les données.
La couche modification des données (Command)
Dans cette couche, on observe davantage d’intermédiaires. Toute modification des données (mise à jour, création, suppression…) passe par cette couche. Ici, chaque action est contextualisée. On ne se contente pas de demander la modification de telle ou telle donnée, la commande porte en elle la notion d’intention : pour quelle raison je souhaite modifier les données. Par exemple, on pourrait avoir une commande ClientDéménage qui impacterait les informations adresse, ville et code postal de l’utilisateur. Dans cet exemple, on sait pourquoi on a modifié ces informations : parce que l’utilisateur a déménagé.
Pour cette partie, on envoie généralement chacune de ces commandes sur un bus, commandes qui seront traitées par des command handlers associées. Ces command handlers vont transmettre les informations de chaque commande au domaine.
Le domaine
Cette zone concentre toute la connaissance métier de l’application. C’est ici que l’on va analyser chaque commande et décider de la suite à donner pour chacune d’entre elles. Ici on trouvera donc les différents objets qui permettront de faire appliquer les règles métiers, de pratiquer les contrôles nécessaires à chaque action etc… Suite à l’analyse de chaque commande, le domaine peut décider de modifier l’état actuel des données. Pour cela, il va générer un ordre de modification : un event.
Les évènements (Events et Event Store)
Ces events sont tous persistés dans ce que l’on appelera l’Event Store que l’on pourrait comparer à un gestionnaire de versions comme SVN par exemple. Chaque event est enregistré et on peut ainsi facilement revenir dans un état antérieur des données ou rejouer par exemple un enchaînement d’events particuliers.
Un système de snapshots permet également de sauvegarder régulièrement l’état du système. On comprend alors facilement l’intérêt d’un tel système en terme d’audit ou de debogage de l’application : on part d’un snapshot sain et on exécute pas à pas chacun des évènements ayant modifié le système jusqu’à trouver l’origine du problème.
A mesure que ces events sont stockés dans l’Event Store, ils sont également publiés sur un bus pour être traités, plus tard, par des Event Handlers. Ce sont eux qui viendront attaquer les données pour répercuter les changements demandés dans chaque event. Ce n’est qu’au terme du traitement de chaque event que les données seront modifiées et persistées.
Avantages et inconvénients
Les avantages
– Architecture adaptée à une infrastructure distribuée
– Chaque action a un impact limité et maîtrisé
– Facilement extensible
– Très pratique pour conserver un historique et ne pas perdre d’informations
Les inconvénients
– Peu utilisé
– Nécessite une plus grande période d’apprentissage
– Peut nécessiter un grand nombre de classes/fichiers, même pour de simples actions
Intégrer CQRS dans votre prochain projet
Bien que récent, ce modèle d’architecture a trouvé de fervents défenseurs qui ont rapidement proposé des frameworks applicatifs pour permettre aux développeurs de toutes technologies d’utiliser CQRS au sein de leurs applications. Voici donc quelques exemples de frameworks pour les environnements les plus connus :
- Axon Framework (Java) : http://www.axonframework.org/
- NCQRS (.Net) : https://github.com/pjvds/ncqrs
- OxyBase (PHP) : http://code.google.com/p/oxybase/



