ETL : définitions, usages…
ETL : “Extract, Transform, Load”
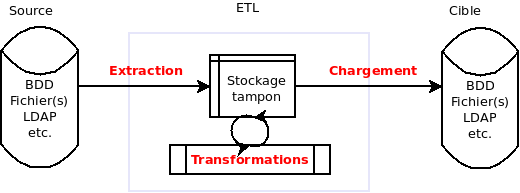
La définition parle d’elle-même : un ETL consiste à extraire des données d’une source de données, les manipuler pour les transformer, et charger ces nouvelles données dans une cible. Sources et cibles peuvent être de n’importe quel type : bases de données, fichiers, web services, etc.
EAI : “Enterprise Application Integration”
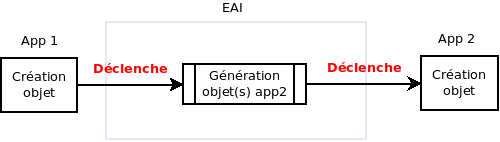
Ici, le but est de faire communiquer les applications du système d’information de l’entreprise entre elles : l’application A1 crée un élément X, et cela doit provoquer la création d’un élément basé sur ce dernier dans l’application A2.
Les grandes différences avec l’ETL : l’aspect “au fil de l’eau”. Une solution EAI passera soit par l’implémentation directement au sein des applications concernées, soit par la mise en place d’un d’évènement déclenchant un ETL ayant pour objectif de créer une donnée sur le système de données A2 à partir d’une donnée du système de données A1.
ELT : “Extract, Load, Transform”
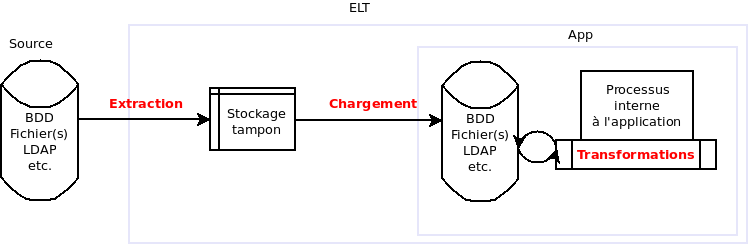
Attention, l’acronyme est très proche, mais on ne parle ici pas du tout de la même façon de réaliser l’opération ! Bien sûr, le principe de fond reste le même : alimenter une cible à partir de données sources. Néanmoins, dans une solution ELT il s’agit d’extraire les données, de les écrire telles quelles dans la base cible, et de les faire transformer ensuite par l’application cible.
La principale différence réside donc dans l’implémentation de la partie “transformation” : il s’agira d’un développement spécifique sur l’application cible, donc dans le langage et l’environnement de cette application, au lieu d’un développement utilisant un outil tiers comme c’est généralement le cas avec un ETL.
Ce système sera envisagé si les transformations sont réellement très complexes et basées sur des règles métier que seule l’application cible peut décemment implémenter.
Dans la réalité, évidemment, on mixera souvent les solutions en fonction de la complexité de la situation :
- Besoin d’une solution EAI mais pas envie de faire un développement spécifique dans une des applications ? On se contente de faire écrire par l’application “A1” des données de type “ordre de transmission” dans une table dédiée (développement minime). C’est ensuite un ETL qui “surveille” cette table régulièrement, et fait son travail sur chaque ligne en supprimant au fur et à mesure. Voilà une EAI basée sur un ETL.
- On a des règles métiers complexes, et on pense donc à un ELT. Néanmoins les données sources sont assez peu pratiques à faire traiter par l’application cible directement : qu’à cela ne tienne, faisons passer les données source dans la moulinette d’un ETL avant de passer la main à l’application cible pour les transformations finales. Un “ETLT” ? Acronymite aigue en vue 😉
Pour aller plus loin
Pour aller plus en profondeur sur ce sujet, je vous conseille le très complet article sur Wikipedia sur le sujet “Extract, Transform, Load” (en anglais).
La suite de l’article se consacrera exclusivement à la présentation d’un des outils disponibles pour implémenter une solution ETL : Talend, dans sa déclinaison Open Studio.
L’outil Talend

Talend est actuellement disponible dans sa version 4.2.3. La série 4.x signe l’entrée dans une ère de professionnalisme, après une série 3.x dont la quantité et la gravité des bugs (jusqu’à la perte totale de travail sur un job) faisait parfois vraiment honte. Ce temps est révolu, et on a aujourd’hui un produit vraiment fiable et stable.
La version 5.0 est en cours de test, et est également disponible au téléchargement. L’outil évolue assez vite au rythme d’une version majeure par an en moyenne, et jusqu’ici toujours dans le bon sens.
Note: dans la version 4.2, la très marketing mention « cloud » se réfère en réalité au support natif des sources de données Marketo, SalesForce et Sugar CRM.
Versions disponibles
La matrice fonctionnelle présentée sur le site de Talend donne des informations complètes :
- Talend Open Studio : L’éditeur en lui-même, on dispose de tous les composants (pas de limitation à ce niveau là) et de l’export en script autonome ou en Web Service. Les fonctionnalités comme le versionning et la génération de documentation sont trop basiques pour être considérées comme vraiment exploitables.
C’est la partie Open Source et gratuite de la suite Talend. Les versions suivantes restent Open Source, mais sont payantes (pas de prix sur le site, c’est à la demande).
- Talend Integration Suite :
- * Team : Cette déclinaison apporte principalement des fonctionnalités de travail collaboratif. Néanmoins, ces fonctionnalités sont intégrées à l’éditeur, ce qui peut être une bonne chose si vous n’utilisez pas déjà un contrôleur de version, mais si vous avez vos habitudes (voire la nécessité pour l’intégration au reste du projet) avec un contrôleur de version déjà en place type SVN ou GIT, cette solution semble peu intéressante. L’idéal aurait été que les sources (description des jobs, format XML) soient bien versionnables telles quelles, ce n’est hélas pas vraiment le cas 🙁 La version « Team » apporte également quelques outils pour le monitoring des jobs, et des wizards supplémentaires. Mais surtout, elle amène la notion de “joblet”: il s’agit de la possibilité d’exporter un job complet (donc tout un process de transformation) en tant que simple composant, réutilisable dans d’autres jobs, ce qui représente un gros plus pour le refactoring et donc la maintenabilité.
- * Pro / Enterprise / MPx / RTx : Par rapport à la “team”, ces versions ajoutent principalement des outils facilitant le déploiement et la gestion de l’exécution (planification, surveillance, reprise sur erreurs…).
Les paragraphes suivants ne détaillent que les fonctionnalités de l’éditeur dans la version Open Studio.
Installation d’Open Studio
Talend Open Studio est un générateur de code Java ou Perl. Si le support de Java est arrivé après coup (dans la version 2), c’est aujourd’hui le langage le mieux supporté, et le mieux fourni en composants communautaires.
L’installation en elle-même est ultra simple : on télécharge une grosse archive sur le site de l’éditeur, on désarchive, et on lance l’exécutable correspondant à son système (Windows, Mac, Linux, 32 bits, ou 64 bits).
Au démarrage, on tombe sur cet écran:
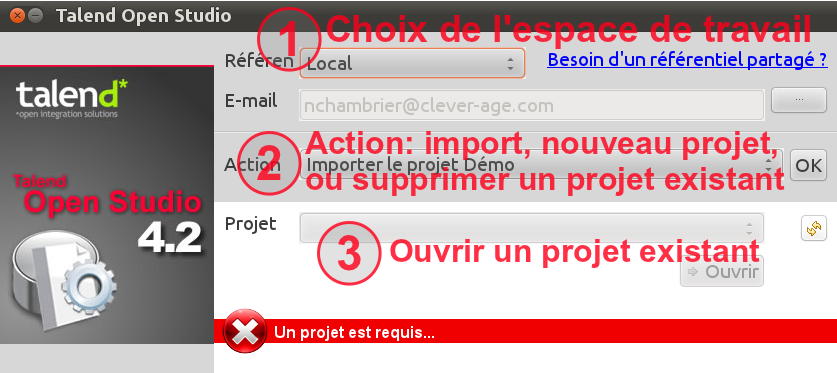
Au premier lancement, on va donc commencer par créer son référentiel local (pour les utilisateurs d’Eclipse, il ne s’agit ni plus ni moins que d’un workspace). Note : le référentiel est lié à une adresse e-mail qui recevra automatiquement la newsletter de Talend (environ 1 mail par quinzaine).
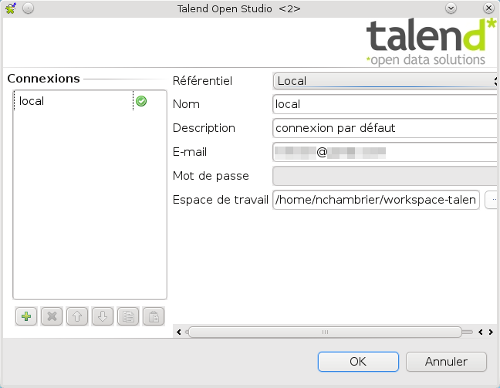
Notez que dans la version 5.0, ce démarrage est extrêmement simplifié:
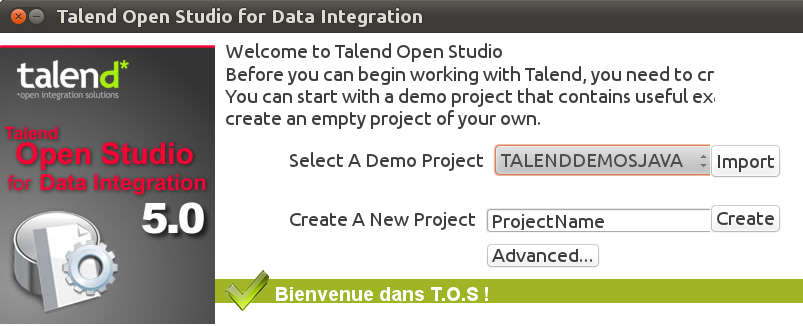
Utilisation d’Open Studio
On va prendre un exemple simple : prendre la liste des fichiers d’un dossier, et écrire cette liste dans un fichier CSV avec seulement les informations « nom », « date de dernière modification », « poids ». Ce petit exemple illustre bien le fait de pouvoir travailler avec des données très hétérogènes (liste de fichiers, contenu d’un FTP, sortie d’une commande shell, fichier CSV, Excel, bases de données, webservices…) sans aucune complexité.
Les bugs connus
- La version 3.2, avec laquelle j’ai démarré, était encore assez fournie en bugs plus ou moins gênants:
- * Modifications de modèle de données mal répercutées sur les composants (assez terrible pour la maintenance).
- * L’export de jobs dans des sous-dossiers échouait irrémédiablement et silencieusement (de beaux .jar vides…).
Ces bugs ont été corrigés dès la 4.0. Cette expérience a montré à la fois l’imperfection de l’outil, mais également la capacité de l’éditeur à le faire évoluer vite et bien.
La série 4.x n’est pas encore exempte de problèmes:
- L’utilisation de trop nombreux composants dans un même job produit un code parfois tellement long qu’il dépasse les capacités du compilateur. Impossible à corriger sans simplement refaire le job en plusieurs morceaux.
- Par défaut les composants de type «
tMap« , quand on veut faire du cache de données sur disque, utilisent le dossier de l’utilisateur qui a effectué la compilation. Concrètement si on se fait piéger en oubliant de spécifier cette valeur, on se retrouve sur le serveur de prod avec des dossiers plein de fichiers temporaires dans un « /home/nom-du-developpeur », ce qui n’est pas terrible… - De la manière dont est généré le code, certaines opérations sont rendues impossibles, comme le fork suivi de la réunification de données:
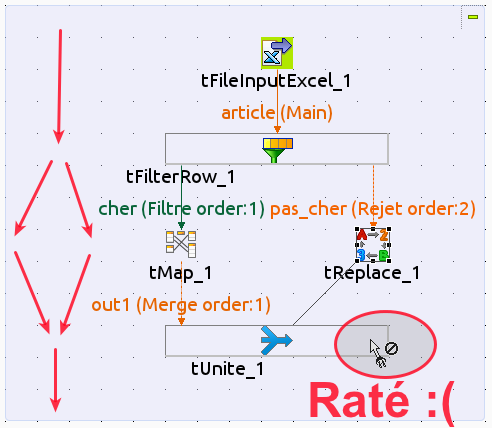
Résumé des avantages/inconvénients
Les inconvénients de Talend Open Studio
- Des bugs sont parfois présents. Du chemin a été fait, et dans la 4.x ils sont maintenant rares, mais encore dans la version précédente il existait des bugs bloquant carrément le déploiement. Ce n’est apparemment pas le cas avec l’Integration Suite.
- L’ergonomie n’est pas toujours au top, et c’est un euphémisme. La version 5 semble toutefois aller dans le bon sens sur ce point.
- Le mode « clicodrome » a ses limites : difficile de versionner les projets, difficile d’expliquer son problème sur un forum sans passer par des screenshots (ce qui rend compliqué l’accès au support sur le forum), et le nombre de clics pour réaliser un job compliqué devient vite incalculable.
- L’effet Eclipse : l’éditeur est très lourd… Pour arranger ça, on peut limiter le nombre de composants dans la palette.
Ses avantages
- Le nombre de composants est proprement impressionnant, et la forge constitue un réservoir à fonctionnalités supplémentaires ;
- Son approche permet de se passer quasiment totalement de connaissances en Java. Dès qu’on souhaitera écrire des expressions, il faudra bien évidemment connaître la base, mais on est très loin de connaissances approfondies, et un grand débutant Java pourra tout-à-fait être productif avec Talend sans difficultés ;
- Le choix de Java comme langage de génération de code permet de s’assurer qu’on aura un script final multi-plateforme. Un script créé, testé, et compilé sous Windows s’exécutera parfaitement sous un environnement Linux – pour peu qu’on ait des JVM compatibles bien sûr… Et cette génération multi-plateforme est bien une réalité que j’ai personnellement vérifiée, pas juste un argument marketing ;
- Il est gratuit, et son code source est disponible, mais il est en même temps supporté par un éditeur et dispose de déclinaisons payantes avec un meilleur support et des fonctionnalités inédites. Cela signifie que quelque soit votre engagement et votre budget, il pourra vous convenir.
Conclusion
Il s’agit d’un très bon outil, sinon le meilleur dans sa catégorie (outil d’extraction et transformation de données en Open Source). Il n’est certes pas parfait, mais offre tout ce qu’on peut attendre d’un outil de ce genre, et on s’habitue vite aux petites imperfections ergonomiques parfaitement insupportables au début 😉
Quelle que soit le contexte, s’il y a des transformations de données à faire (et c’est une situation plus que fréquente…), une solution “ETL” doit au moins être envisagée, et dans ce cas Talend sera souvent un bon choix.



