Dans notre dernière chronique : «comment organiser sa gestion documentaire ?», nous avons présenté les techniques d’indexation de documents. Si celles-ci autorisent des recherches lexicales ou sur des bases de «mots-clés», elles ne permettent pas d’effectuer des recherches sémantiques (prenant en compte le sens des mots). Pour ce faire, une suite d’analyses linguistiques est nécessaire.
Les analyses documentaires
Le but est de parvenir à dégager le sens des mots et des phrases constituant le contenu, ce afin d’affiner les rapports contextuels entre les documents et répondre ainsi plus précisément à des besoins métiers. Avant de pouvoir opérer l’analyse sémantique, il faut au préalable passer par plusieurs étapes d’analyse : l’analyse morphologique et l’analyse syntaxique.
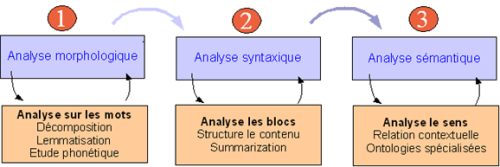
Outre ces trois types d’analyse, un dernier type sera présenté ; il est utilisé pour la restitution des résultats d’une recherche : l’analyse statistique. Nous aurons ainsi fait le tour des différents types d’analyse documentaire possibles.
L’analyse morphologique
Ce type d’analyse, mis en place par F. Zwicky lors de la seconde guerre mondiale, explore les futurs possibles d’un objet en le décomposant et en étudiant toutes ses combinaisons natives. En clair, il s’agit de développer chaque mot d’un texte dans toutes les formes qu’il peut avoir (ce travail rappelle les analyses que font les enfants dans les classes primaires pour assurer leur compréhension globale de la phrase).
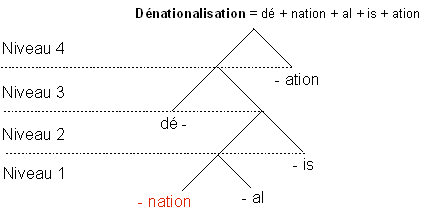
Dans un premier temps, cette analyse développe les termes, ce qui permet de connaître leur racine propre ; dans un deuxième temps, elle va chercher à découvrir la nature et la fonction de chaque terme dans la phrase. Elle pourra alors détecter sa signification réelle et supprimer de nombreux litiges. Exemple : ‘un as de pique’ ne fait pas référence au verbe avoir du présent à la deuxième personne du singulier.
L’analyse syntaxique
Il s’agit de regrouper les unités lexicales en structures grammaticales, afin de comprendre la structure d’un texte. Elle peut extraire une qualification affinée des documents soumis, et organiser une structure imbriquée du document
(un exemple d’analyseur syntaxique).
A ce stade il est donc possible de rassembler des corpus de textes, en basant la recherche sur :
– des verbes, des adjectifs qualificatifs, des noms Propres…
– un champ lexical (les mots d’une même phrase)
– des grammaires spécifiques (par exemple, les paragraphes contenant les mots X et Y dans une même phrase)
– ect.
L’analyse syntaxique donne accès à une hiérarchisation très ségmentée du texte, et est donc très utile pour résumer des contenus.
L’analyse sémantique
L’analyse sémantique a pour but de faire ressortir le sens profond du document en cherchant à répondre aux questions de contexte : Qui ? Quoi ? Où ?… La réponse à ces questions se fait grâce à des algorithmes de gestion de Thesaurus métier qui trouvent les chemins d’un terme jusqu’à tous ses concepts voisins, parents, dérivés, etc.
Les thésaurus les plus communs harmonisent la communication et le traitement de l’information en reliant :
– Les termes génériques
– Les termes spécifiques
– Les termes équivalents
– Les termes associés
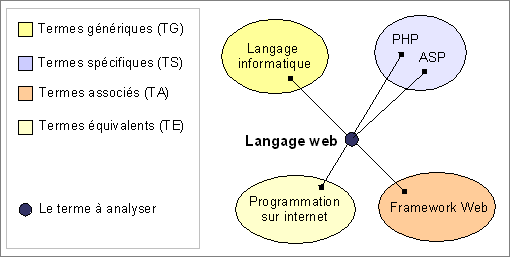
Il existe de nombreuses possibilités sur les types de liaisons qui rattachent deux terme, et le système pourra prendre en compte:
– l’appartenance (un « lexème » appartient à un « lexique »)
– l’attribut (« passé » et « futur » sont des attributs de « temps »)
– la causalité (« L’anthrax a tué un américain »)
– l’hypéronymie / l’hyponimie (voir une définition de ces termes)
– les liens connexes (« souris » et « clavier » sont des concepts proches)
– les métonymies / synecdotes
– la production (« Lotus » produit par « IBM »)
– la substance (la « baignoire » est en « fonte »)
– la succession
– la synonymie/ l’antonymie
– etc.
Les thesaurus les plus répandus concernent généralement un domaine précis (le calcul mathématique, la médecine, la recherche en aérodynamique, etc.). Il n’existe pas encore de solution standardisée par domaine dans une structure universelle ; les recherche
en RDF/XML annonceront peut être un jour la sortie d’une ontologie homogène pour tous.
Face à ce manque de standardisation, les systèmes d’aujourd’hui exécutent leurs analyses en partant depuis un thesaurus vide et exploitent les processus de catégorisation automatique, créant ainsi un dictionnaire adapté à leur entreprise.
Cette étude au niveau du sens offre bien souvent la possibilité de faire des recherches en langage naturel [ [Langage naturel par Spirit ]]. Cela signifie que l’utilisateur pose sa question à la machine comme à un interlocuteur normal, et que le moteur est capable d’interpréter et de traduire cette demande en une équation spécifique.
Pour en savoir plus :
– Analyse sémantique par Semantis
L’analyse statistique
Dans le cadre d’une recherche, après une requête utilisateur, les résultats sont trop désordonnés pour être exploitables ; ils ont tous un lien direct avec la question de l’utilisateur mais ils ne sont pas classés. L’analyse statistique capitalise la pertinence des
réponses et les présente selon l’ordre le plus adéquat à la demande. Des calculs de probabilité permettent de mieux comprendre les utilisateurs et de fixer progressivement leurs intérêts propres, en gardant en mémoire ses recherches précalculées.
Le système mis en place doit être capable de prendre en compte la position hiérarchique de chaque utilisateur : d’une part, celui-ci doit être guidé vers les documents qui sont le plus en rapport avec son activité ; d’autre part, le système doit assurer la sécurité et la confidentialité des résultats, selon un workflow documentaire configurable et éprouvé.
L’analyse statistique est aussi capable de fournir aux utilisateurs une assistance visuelle de recherche offrant tous les éléments d’aide à la prise de décision. Il peut s’agir de plusieurs choses différentes et non incompatibles :
– des arbres de recherche classés par sujet, concept, auteur, date, type de documents, etc. ;
– une adéquation entre l’utilisateur et le système (question/réponse pour éviter les dialogues de sourds, en interrogeant l’utilisateur face à certains litiges, et en lui suggérant des solutions de réponses cadrées dans son métier) ;
– des réseaux d’alertes automatiques et paramétrables afin de se tenir au courant des évolutions de ses centres d’intérêt, sur tout un patrimoine documentaire et sur internet (veille concurrentielle).
Les interfaces de recherche
Chaque moteur de recherche met en place un dialogue entre l’utilisateur et le système. Il y a deux phases distinctes : la formulation de la question et la présentation des résultats.
Avant de parcourir la classification documentaire, le sytème doit étudier la question elle même. Celle-ci peut en effet contenir des fautes, des termes dérivés par rapport à un contexte souhaité, des syntaxes approchées, etc. On peut rechercher quelque chose de simple en formulant une grande quantité de termes, ce qui peut aussi controverser ou embrouiller la demande ; le système doit alors réduire la question à sa valeur utile. Le moteur passe par des traitements (semblables aux analyses documentaires) qui traduisent la demande de l’utilisateur en équation appropriée au système et peuvent retourner beaucoup d’informations contextuelles avoisinant la recherche (voir par exemple l’interface d’exalead).
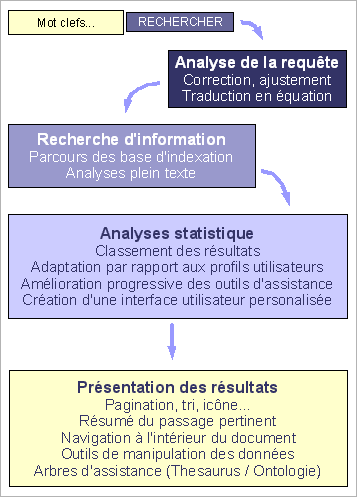
En ce qui concerne la présentation, le résultat final se solde par une liste d’éléments renvoyés, à laquelle s’adjoignent de multiples services. L’interface la plus classique:
– affiche le nombre de résultats trouvés et la pertinence associée à chaque réponse ;
– associe chaque résultat à une une icone (type de document) ;
– donne un descriptif (résumé) du passage pertinent.
Pour permettre une plus grande souplesse de visualisation des objets trouvés, l’interface doit :
– offrir une pagination d’affichage modulable (nombre de résultats par page) ;
– rappeller la requête formulée par l’utilisateur et suggérer des requêtes avoisinnantes ;
– permettre le tri des résultats selon les caractéristiques de chaque document (par date, par pertinence, par auteur, par thèmes voisins, etc.) ;
– etc.
Si une réponse est sélectionnée, le système doit fournir des outils pour consulter la partie intéressante du document dans un format natif (xls, doc, pdf…) avec une mise en évidence visuelle des éléments caractéristiques. Des raccourcis permettent d’exploiter facilement l’information intéressante (impression, copier/coller, envoyer à quelqu’un, etc.). L’ergonomie simple et soignée sera le reflet d’une meilleur prise en main du système, pour toutes les cibles utilisatrices (accessibilité, simplicité, flexibilité).
Pour en savoir plus, voici quelques moteurs de recherche spécifiques à un métier:
– moteur cartographié de kartoo
– moteur juridique francophone
– moteur d’Ariane, qui peut associer 1100 résultats de moteurs de recherche
– un annuaire de moteur de recherche
– les relations entre les moteurs de recherche
Se munir d’un tel système au sein de son système d’information n’implique pas forcément une remise en question de tous ses outils. Ce sont généralement des briques relativement indépendantes et interchangeables ; et qui plus est quasiment transparentes pour les usagers : tout au plus, une légère modification des interfaces peut se révéler nécessaire afin d’incorporer les nouvelles fonctionnalités du moteur de recherche.
L’amélioration de la puissance du moteur de recherche contribuera à augmenter la productivité des employés et par là la performance de l’entreprise.
Conclusion
D’un patrimoine désordonné, on peut construire un ensemble organisé, hierarchisé, catographié, qui simplifie efficacement la réutilisation des documents. Le cheminement à suivre pour ordonner son système se fait par la collecte des sources de données, l’indexation concise de son univers (concept, segment, sous-segment…), l’exécution d’analyses documentaires en plein texte et le choix d’interfaces de recherche à implémenter. A chacune de ces phases, on choisira en option les services secondaires que l’on souhaite ajouter afin de rendre le système plus ergonomique.
Ces systèmes de recherche et d’indexation se révèlent même aujourd’hui être indispensables pour certains métiers spécifiques
(la médecine, le français médiéval, etc.). A chaque entreprise d’établir son mode de fonctionnement pour connaître ses besoins réels. De nombreuses sociétés sont spécialisées dans le domaine et proposent du conseil pour choisir le meilleur produit, inventorier les services secondaires à ajouter ou encore effectuer l’installation totale du système d’indexation et de recherche (voir ce panorama d’outils).



